Prufa
AI QA engineer for web products. Know your app works.
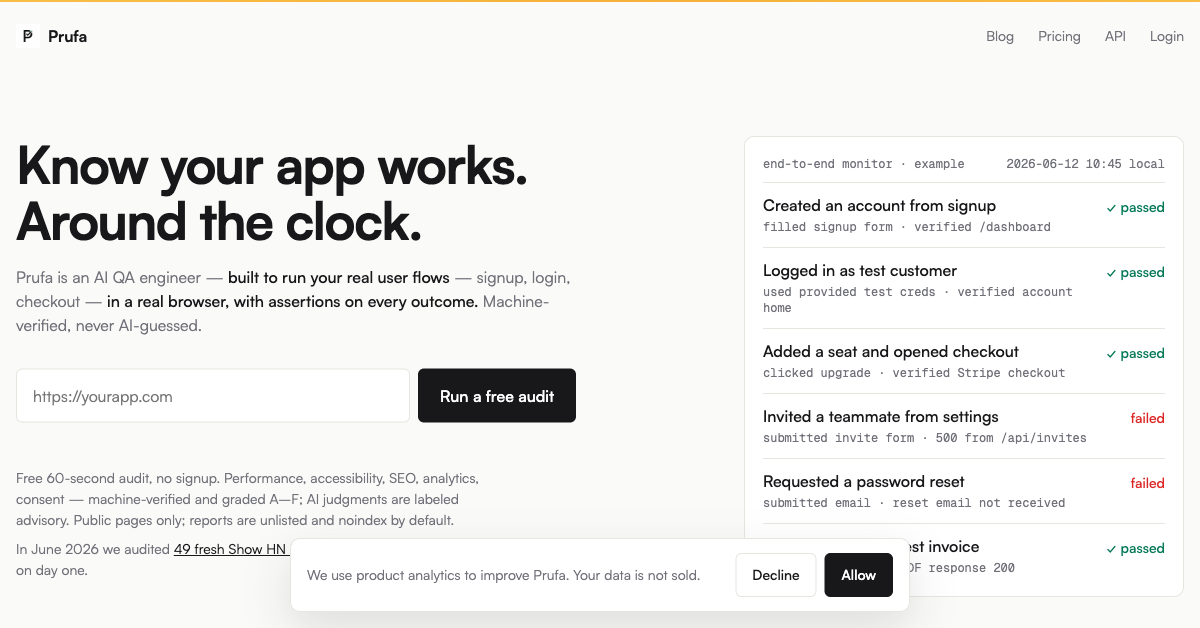
Prufa is an AI QA engineer for web products, built for the agentic era. An LLM-backed agent navigates your app like a real user — signup, login, checkout — and plain code verifies every result. Verified findings are machine-checked with evidence; LLM judgments are clearly labeled advisory and never graded as facts. Humans get a dashboard, shareable reports, and Slack alerts; AI agents get a CLI, versioned HTTP API, MCP server, and an agent skill — the same product through both surfaces. Try the free 60-second audit: paste a URL, no signup.
Features
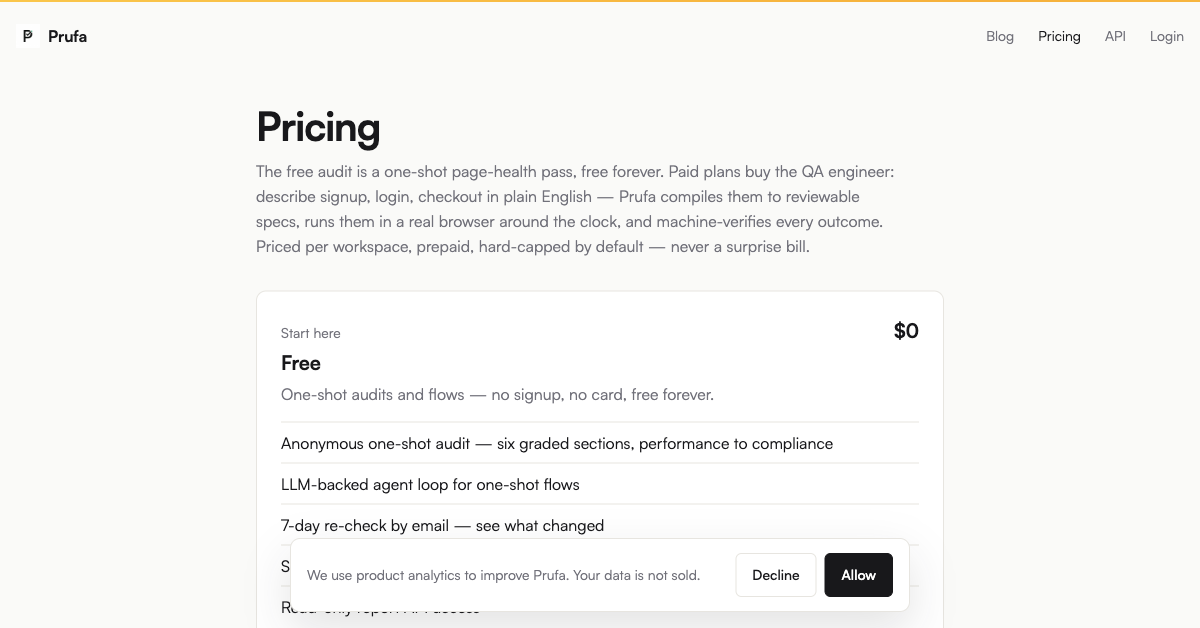
Free 60-second audit: paste a URL, no signup
Real-browser flow testing: signup, login, checkout
Machine-verified findings with evidence; LLM judgments labeled advisory
Scheduled monitoring with Slack alerts and shareable reports
Agent surface: CLI, versioned OpenAPI-published API, MCP server, agent skill
Prepaid plans with hard caps by default; idempotent, retry-safe API
Use Cases
Pre-launch QA: run a free audit before shipping and catch broken analytics, links, and console errors
Flow regression testing: verify signup, login, and checkout still work after every deploy
Production monitoring: scheduled runs with Slack alerts when a flow breaks
Agent workflows: let your AI coding agent QA its own work via MCP server or API

Comments


Hi! I'm Gregory, solo founder of Prufa. I built it because launch-day bugs are systematic: we audited 49 fresh Show HN launches with Prufa's own free audit and 78% had a critical bug (38 of 49 shipped analytics that recorded zero events). The core idea: an LLM-backed agent navigates your app like a real user, but plain code does all the grading against captured browser evidence — so findings are machine-verified, never AI-guessed. The free 60-second audit needs no signup: paste a URL on prufa.dev. Agents are first-class users too: CLI, versioned API, MCP server, agent skill. Happy to answer anything!




The verified-vs-advisory split is exactly the right call for trust in a QA tool. What I'm curious about: testing signup/login/checkout against a live app means the agent creates real accounts and maybe real orders. On scheduled production runs, how do you keep it from polluting the app with junk signups or triggering real charges — test-mode hooks, a sandbox-account convention, automatic teardown? That's usually where "real-user flow testing" gets scary to point at prod.

Premium Products




































Sponsors
BuyMakers
Makers
Comments
Hi! I'm Gregory, solo founder of Prufa. I built it because launch-day bugs are systematic: we audited 49 fresh Show HN launches with Prufa's own free audit and 78% had a critical bug (38 of 49 shipped analytics that recorded zero events). The core idea: an LLM-backed agent navigates your app like a real user, but plain code does all the grading against captured browser evidence — so findings are machine-verified, never AI-guessed. The free 60-second audit needs no signup: paste a URL on prufa.dev. Agents are first-class users too: CLI, versioned API, MCP server, agent skill. Happy to answer anything!
The verified-vs-advisory split is exactly the right call for trust in a QA tool. What I'm curious about: testing signup/login/checkout against a live app means the agent creates real accounts and maybe real orders. On scheduled production runs, how do you keep it from polluting the app with junk signups or triggering real charges — test-mode hooks, a sandbox-account convention, automatic teardown? That's usually where "real-user flow testing" gets scary to point at prod.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved