
RunDoc
AI-powered runbooks and SOPs for DevOps teams
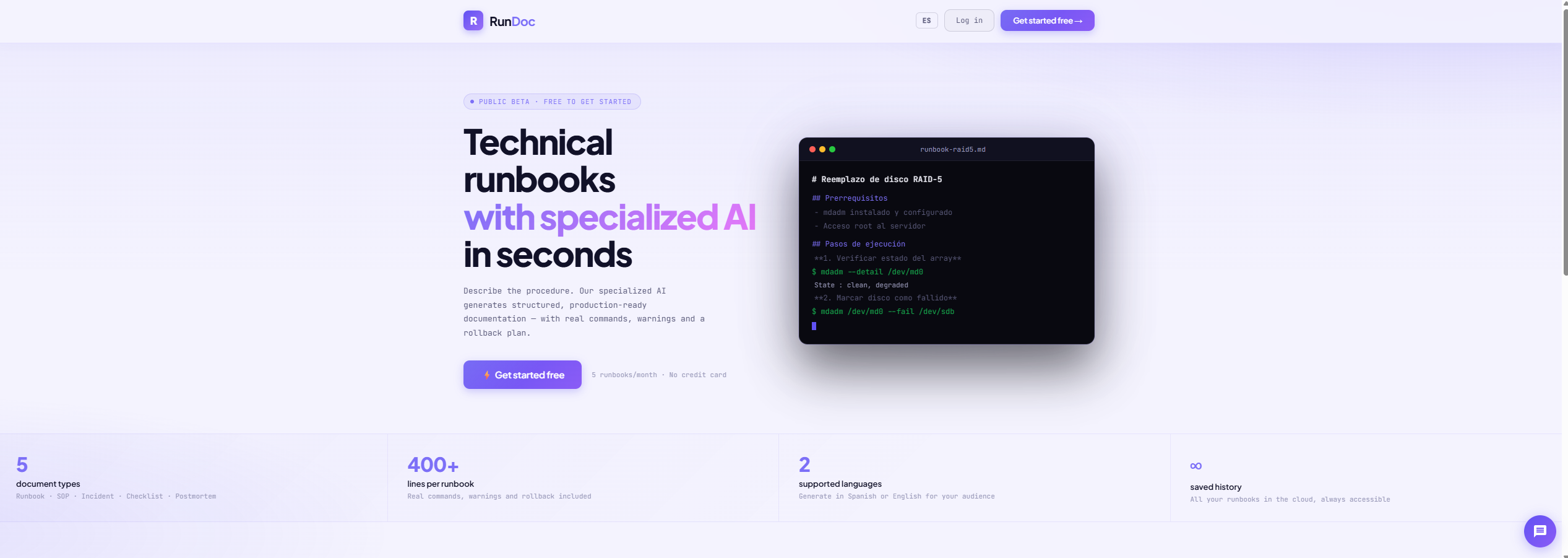
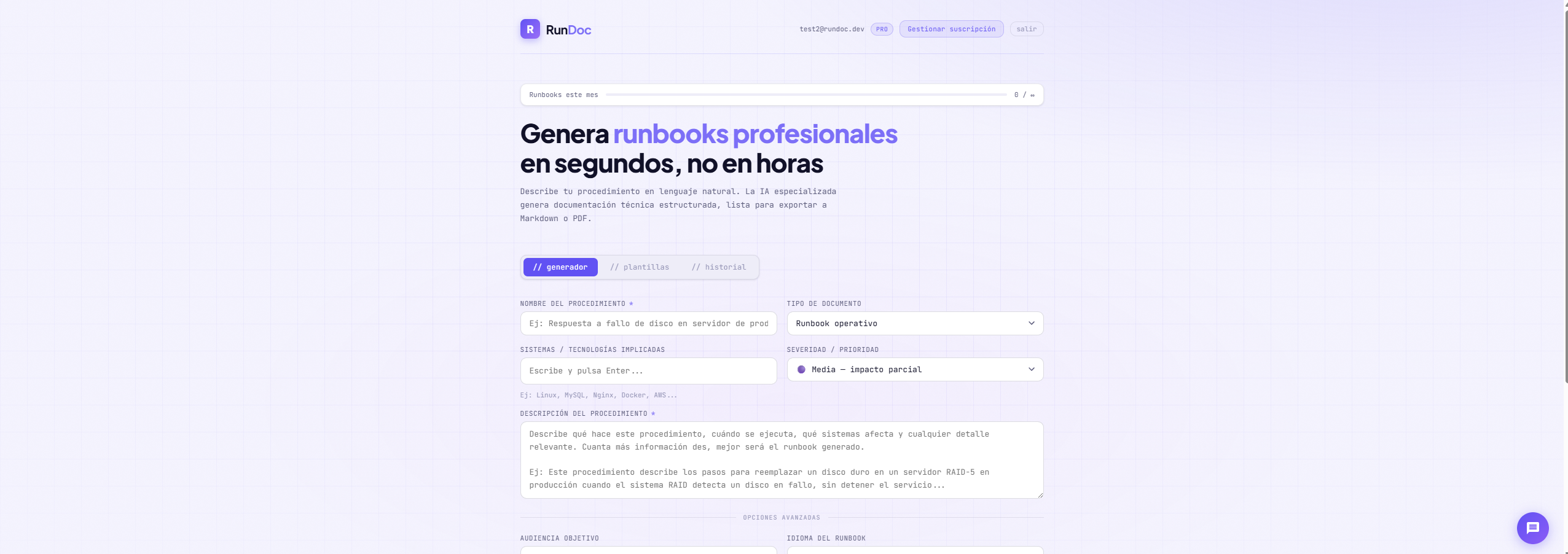
RunDoc generates production-ready runbooks, SOPs, incident guides and postmortems in seconds. Describe your procedure and get structured documentation with real commands, warnings and rollback plans — no more writing docs from scratch at 3am during an incident.
Pro plan includes AI Council: 4 LLMs (GPT-4o, Gemini, Claude, Grok) generate the runbook independently, cross-review each other's output, and a Chairman model synthesizes the final version. The result is noticeably denser documentation with fewer assumptions and better rollback coverage.
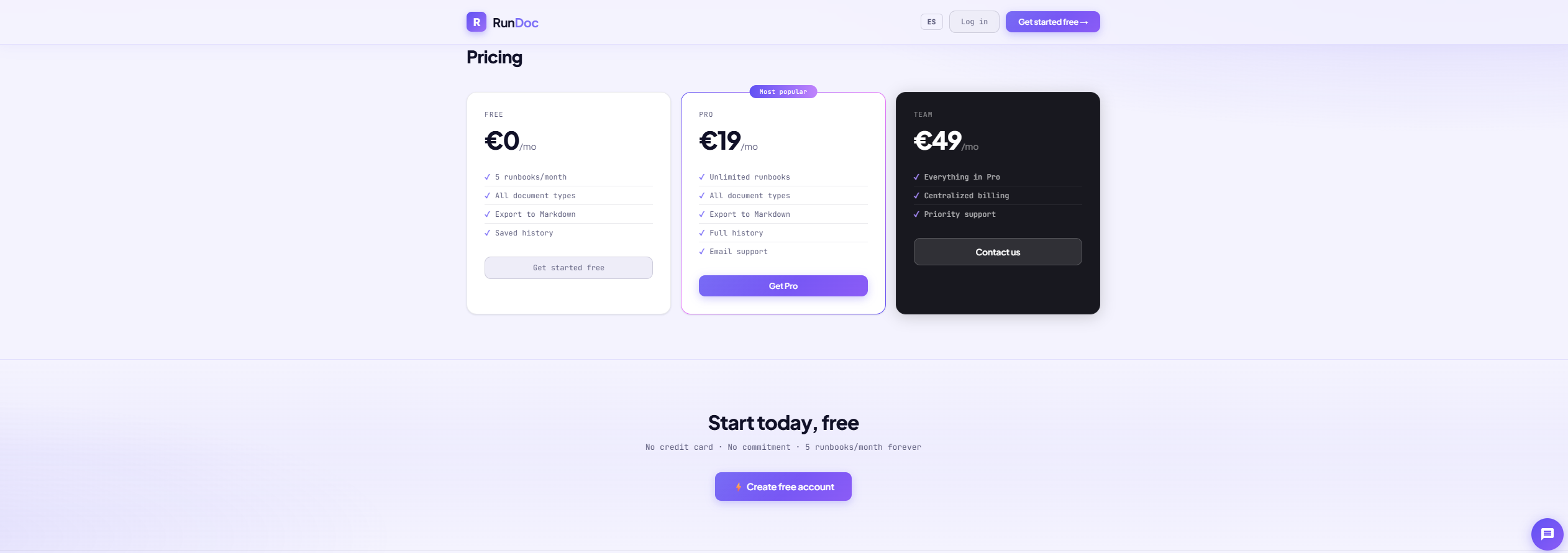
Free plan available — 5 runbooks/month, no card required.
Features
✅ Instant runbook generation from a simple description
✅ SOPs, incident guides, checklists and postmortems
✅ Real commands, warnings and rollback plans included
✅ AI Council (Pro): 4 LLMs cross-review each other's output
✅ Chairman model synthesizes the final version
✅ No templates, no manual formatting
✅ Free plan — 5 runbooks/month, no credit card required
Use Cases
🔥 On-call engineer needs a runbook fast during an incident
🔧 SRE documenting a new deployment procedure
🔄 DevOps team standardizing rollback processes
📋 SysAdmin creating SOPs for repetitive maintenance tasks
🚨 Incident response documentation and postmortems
☸️ Kubernetes cluster operations and troubleshooting guides
🗄️ Database migration and backup procedures
🔐 Security incident response playbooks
Fazier Deal

Comments


I built RunDoc after spending years in DevOps watching engineers write the same runbooks from scratch during incidents. The AI Council feature — where 4 LLMs cross-review each other's output — came from frustration with single-model hallucinations in critical procedures. Happy to answer any questions about the architecture or use cases.

I like the direction here. Runbooks + SOPs always end up being either too static or too scattered across tools, so having a more AI-driven layer makes sense. What stood out to me is the focus on turning operational knowledge into something executable. That’s usually where most AI productivity tools fail they stop at generation instead of workflow integration. Curious how you handle versioning of SOPs when teams start iterating fast.




The AI Council angle is clever — having GPT-4o, Gemini, Claude and Grok cross-review before a Chairman synthesizes is a smart way to cut hallucinated commands, which is the real risk with auto-generated runbooks. One genuine question: do the rollback plans get validated against the user's actual stack/environment, or is that still on the engineer to verify before an incident? The 3am-during-an-incident framing really nails the pain point.


The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.





The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.
The multi-LLM cross-review approach is a genuinely smart architectural choice for runbooks — single-model hallucinations in incident procedures could be catastrophic. Curious whether the Chairman model selection impacts output quality significantly, and if teams can customize the synthesis rules for their specific infrastructure stack. The free tier at 5 runbooks/month is generous enough to actually validate the tool before committing.
The multi-LLM cross-review approach is a genuinely smart architectural choice for runbooks. Single-model hallucinations in incident procedures could be catastrophic in production. The free tier at 5 runbooks/month is generous enough to validate the tool before committing. Would love to know if teams can customize the synthesis rules for their specific infrastructure stack.

This is a really clever approach to solving the hallucination problem in production environments. Having multiple LLMs cross-review the commands before a Chairman model finalizes the runbook is a solid design choice for infrastructure documentation where mistakes are high-stakes. Congrats on the launch!

The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.

the AI Council design is the standout here. most multi-LLM products just let you switch models — you're making them check each other, which matches my experience building on top of multiple AIs: the disagreement between models is where the real information lives, and a single model reviewing its own output never catches its own blind spots. one question on the Chairman step: when the four runbooks genuinely conflict (say, two different rollback strategies), does the synthesizer pick one, merge them, or surface the conflict to the user? for incident docs specifically, i'd almost want to see the disagreement — "models disagreed here" is itself a warning that the procedure has ambiguity. either way, "no more writing docs at 3am during an incident" is a painfully well-chosen pitch.


I really love the clean, no-nonsense approach you've taken here. So many tools in this space get bloated with unnecessary features, but this looks completely focused on core utility. Are you planning to prioritize any third-party integrations (like Slack, Notion, or Webhooks) in your upcoming roadmap?

The 3am incident scenario is exactly right — that's when docs either save you or don't exist. The AI Council approach is genuinely interesting: having four models cross-review each other before synthesis is a smart way to catch blind spots that a single model confidently skips. Would be curious whether the Chairman model is fixed GPT-4o?) or rotates — and whether teams can see the individual model outputs before the synthesis, or just the final version.

Finally a tool that actually does the work instead of just throwing data at you. I've been using eRank for months and always hit that wall — great keyword data, but then you're staring at a blank listing wondering how to put it all together. The one-click rewrite is exactly what Etsy sellers need. Tried the free score on my first listing and it flagged issues I'd completely missed. Solid product.

Premium Products





































Fazier Deal
Sponsors
Buy

Makers
Makers
Comments
I built RunDoc after spending years in DevOps watching engineers write the same runbooks from scratch during incidents. The AI Council feature — where 4 LLMs cross-review each other's output — came from frustration with single-model hallucinations in critical procedures. Happy to answer any questions about the architecture or use cases.
I like the direction here. Runbooks + SOPs always end up being either too static or too scattered across tools, so having a more AI-driven layer makes sense. What stood out to me is the focus on turning operational knowledge into something executable. That’s usually where most AI productivity tools fail they stop at generation instead of workflow integration. Curious how you handle versioning of SOPs when teams start iterating fast.
The AI Council angle is clever — having GPT-4o, Gemini, Claude and Grok cross-review before a Chairman synthesizes is a smart way to cut hallucinated commands, which is the real risk with auto-generated runbooks. One genuine question: do the rollback plans get validated against the user's actual stack/environment, or is that still on the engineer to verify before an incident? The 3am-during-an-incident framing really nails the pain point.
The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.
The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.
The multi-LLM cross-review approach is a genuinely smart architectural choice for runbooks — single-model hallucinations in incident procedures could be catastrophic. Curious whether the Chairman model selection impacts output quality significantly, and if teams can customize the synthesis rules for their specific infrastructure stack. The free tier at 5 runbooks/month is generous enough to actually validate the tool before committing.
The multi-LLM cross-review approach is a genuinely smart architectural choice for runbooks. Single-model hallucinations in incident procedures could be catastrophic in production. The free tier at 5 runbooks/month is generous enough to validate the tool before committing. Would love to know if teams can customize the synthesis rules for their specific infrastructure stack.
This is a really clever approach to solving the hallucination problem in production environments. Having multiple LLMs cross-review the commands before a Chairman model finalizes the runbook is a solid design choice for infrastructure documentation where mistakes are high-stakes. Congrats on the launch!
The multi-LLM cross-review approach for runbooks is a smart design choice. Single-model outputs for critical infrastructure docs can miss edge cases or hallucinate commands — having 4 models independently generate then synthesize should catch those gaps. Curious whether the free tier's 5 runbooks/month resets or accumulates, and if there are plans to support custom templates for teams with specific compliance requirements.
the AI Council design is the standout here. most multi-LLM products just let you switch models — you're making them check each other, which matches my experience building on top of multiple AIs: the disagreement between models is where the real information lives, and a single model reviewing its own output never catches its own blind spots. one question on the Chairman step: when the four runbooks genuinely conflict (say, two different rollback strategies), does the synthesizer pick one, merge them, or surface the conflict to the user? for incident docs specifically, i'd almost want to see the disagreement — "models disagreed here" is itself a warning that the procedure has ambiguity. either way, "no more writing docs at 3am during an incident" is a painfully well-chosen pitch.
I really love the clean, no-nonsense approach you've taken here. So many tools in this space get bloated with unnecessary features, but this looks completely focused on core utility. Are you planning to prioritize any third-party integrations (like Slack, Notion, or Webhooks) in your upcoming roadmap?
The 3am incident scenario is exactly right — that's when docs either save you or don't exist. The AI Council approach is genuinely interesting: having four models cross-review each other before synthesis is a smart way to catch blind spots that a single model confidently skips. Would be curious whether the Chairman model is fixed GPT-4o?) or rotates — and whether teams can see the individual model outputs before the synthesis, or just the final version.
Finally a tool that actually does the work instead of just throwing data at you. I've been using eRank for months and always hit that wall — great keyword data, but then you're staring at a blank listing wondering how to put it all together. The one-click rewrite is exactly what Etsy sellers need. Tried the free score on my first listing and it flagged issues I'd completely missed. Solid product.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved