
OCRMD
Transform PDF documents and images into editable Markdown
Transform your PDFs into editable Markdown in seconds!
OCR Markdown is a powerful OCR solution that transforms scanned documents, image files, and non-selectable PDFs into editable Markdown. Its free, client-side OCR runs entirely in the browser on images, requiring no account and offering basic text extraction. The Premium model extends support to PDFs, delivers AI-enhanced text recognition with formatting, math, table, and image detection at 90–99% accuracy, securely stores uploads and results for document organization and full-text search, and lets you download results anytime, from anywhere. By eliminating manual transcription, OCR Markdown streamlines content workflows and makes unsearchable text instantly accessible and reusable.
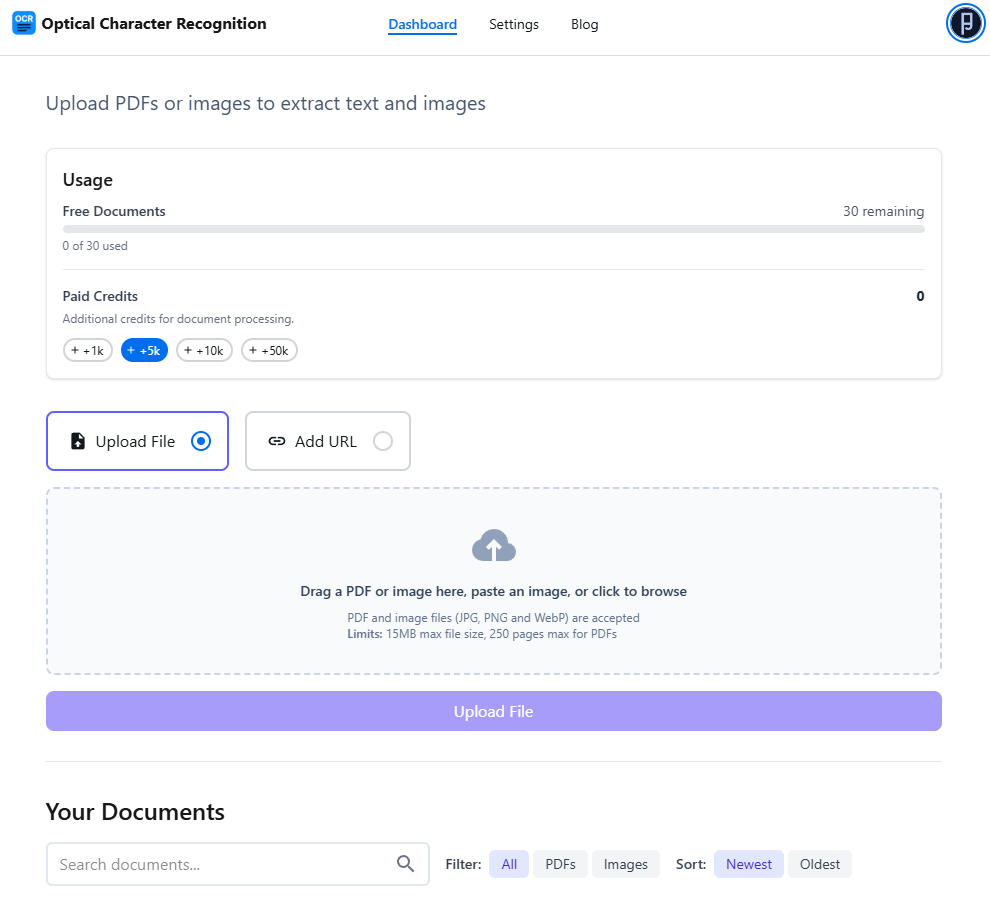
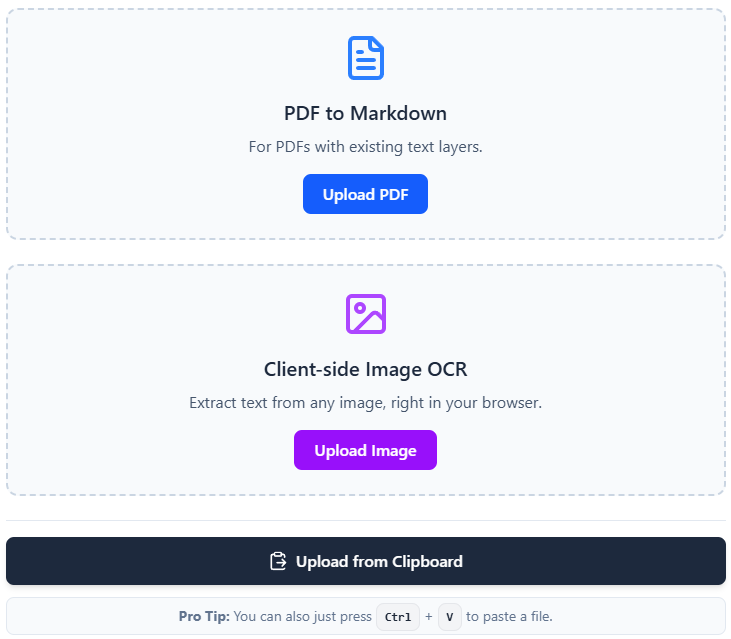
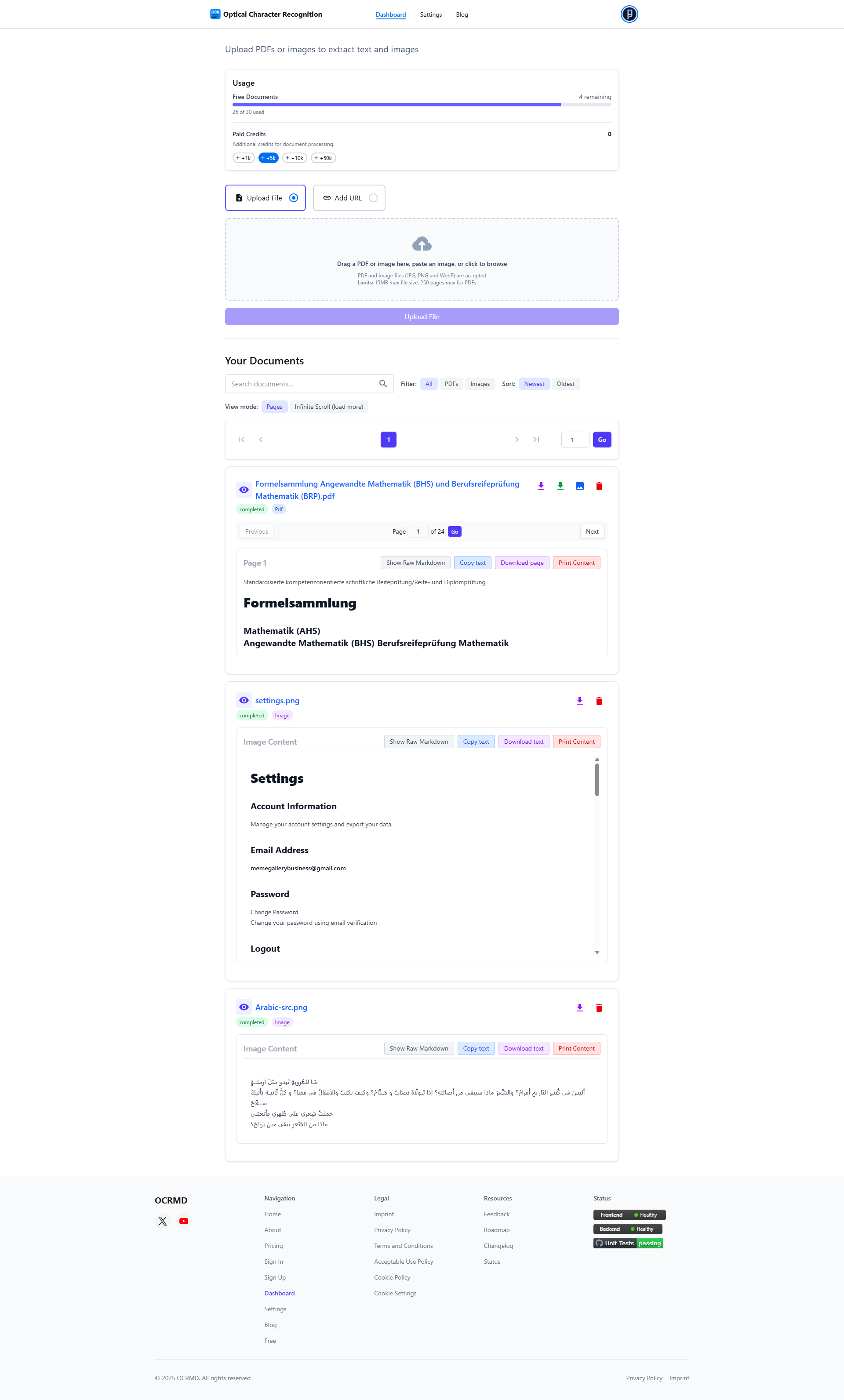
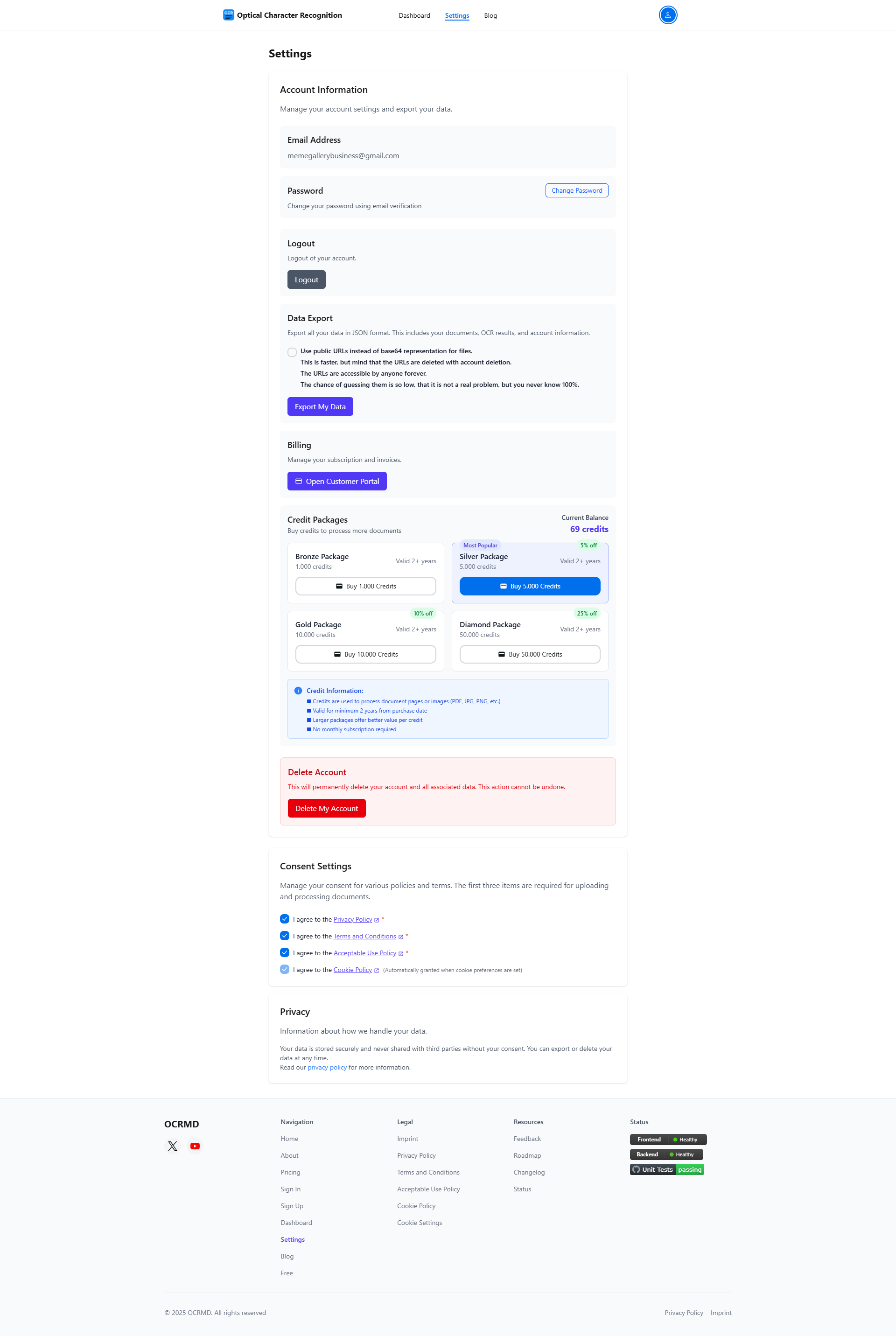
Features
OCR Markdown (OCRMD) is a user-friendly OCR tool that converts scanned documents, images, and non-selectable PDFs into editable Markdown or LaTeX. The free, browser-based version allows you to extract and convert up to 30 pages or images per session, with no signup required. It supports quick text extraction, including PDF text-layer extraction, and operates entirely client-side for privacy. Upgrading to Premium unlocks advanced, AI-enhanced OCR with 90–99% accuracy, better formatting recognition (including maths, tables, and images), full PDF support, secure cloud storage, powerful document organization, and full-text search. This helps streamline document workflows and makes previously unsearchable text easy to access and reuse.
Use Cases
OCR Markdown (OCRMD) is ideal for converting scanned documents, images, and non-selectable or problematic PDFs into editable and searchable Markdown or LaTeX. Use cases include:
- Academic and Research Work: Convert research articles, scientific papers, or scanned notes into editable formats for easy citation and collaboration.
- Digitizing Printed Documents: Make printed contracts, forms, and letters accessible and editable without manual re-typing.
- PDFs with Broken Text or Rasterized Content: Extract correct, usable text from PDFs that display garbled characters, have incorrect unicode encoding, or are completely image-based (rasterized), where regular copy-pasting fails.
- Archive and Library Management: Turn archival scans or problematic PDFs into searchable, organized text for digital libraries or content management.
- Blogging and Publishing: Convert screenshots, book pages, or legacy PDFs into Markdown for content migration or direct publishing.
- Math and STEM Projects: Extract and edit mathematical formulas, tables, and scientific content, streamlining LaTeX editing for researchers and students.
- Code and Documentation: Reuse code snippets or documentation from images or poorly encoded PDFs for faster integration into codebases or technical wikis.
- Personal Productivity: Digitize and search personal notes, receipts, and other records—even if the original files have broken, unselectable, or image-only text.
This expanded list highlights OCRMD’s ability to make even the most inaccessible, poorly encoded, or rasterized documents quickly reusable and searchable.

Comments


There are a lot of OCR solutions on the web. The problem is that most of them only extract basic text, even if they are paid services. I needed a solution that could extract markdown and LaTeX as well as images, so I created OCRMD.com. I also needed a proper dashboard for viewing extracted content rendered with markdown and LaTeX formatting, so I built one. Additionally, I wanted to be able to export the extracted markdown as PDF to make it easier to share with others.






Premium Products




































Sponsors
BuyAwards
View all
Awards
View allMakers
Makers
Comments
There are a lot of OCR solutions on the web. The problem is that most of them only extract basic text, even if they are paid services. I needed a solution that could extract markdown and LaTeX as well as images, so I created OCRMD.com. I also needed a proper dashboard for viewing extracted content rendered with markdown and LaTeX formatting, so I built one. Additionally, I wanted to be able to export the extracted markdown as PDF to make it easier to share with others.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved