
LongCat Flash AI
Meituan's open-source 560B parameter LLM with blazing speed
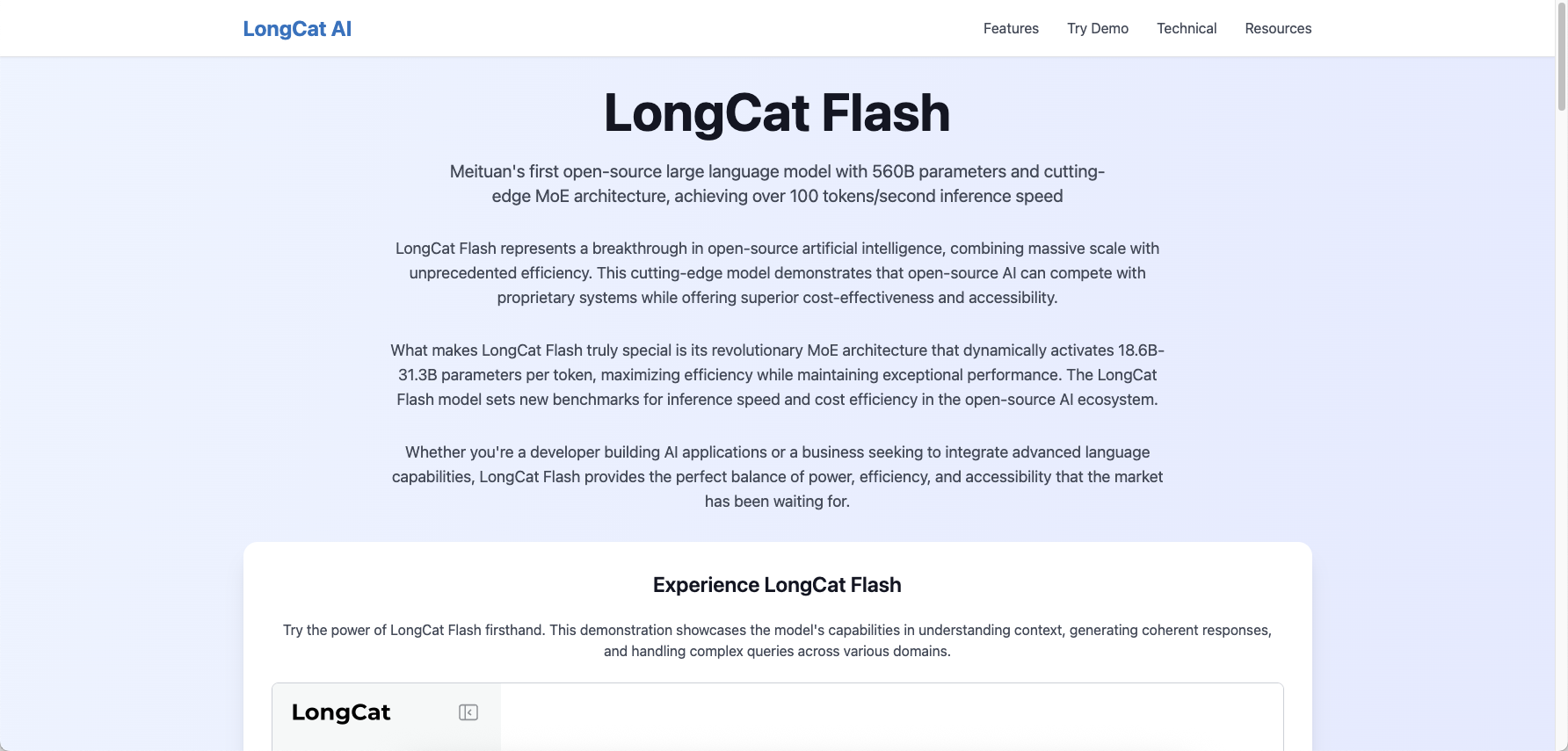
LongCat AI is Meituan's revolutionary open-source large
language model featuring 560B parameters with innovative
Mixture-of-Experts (MoE) architecture. It delivers exceptional
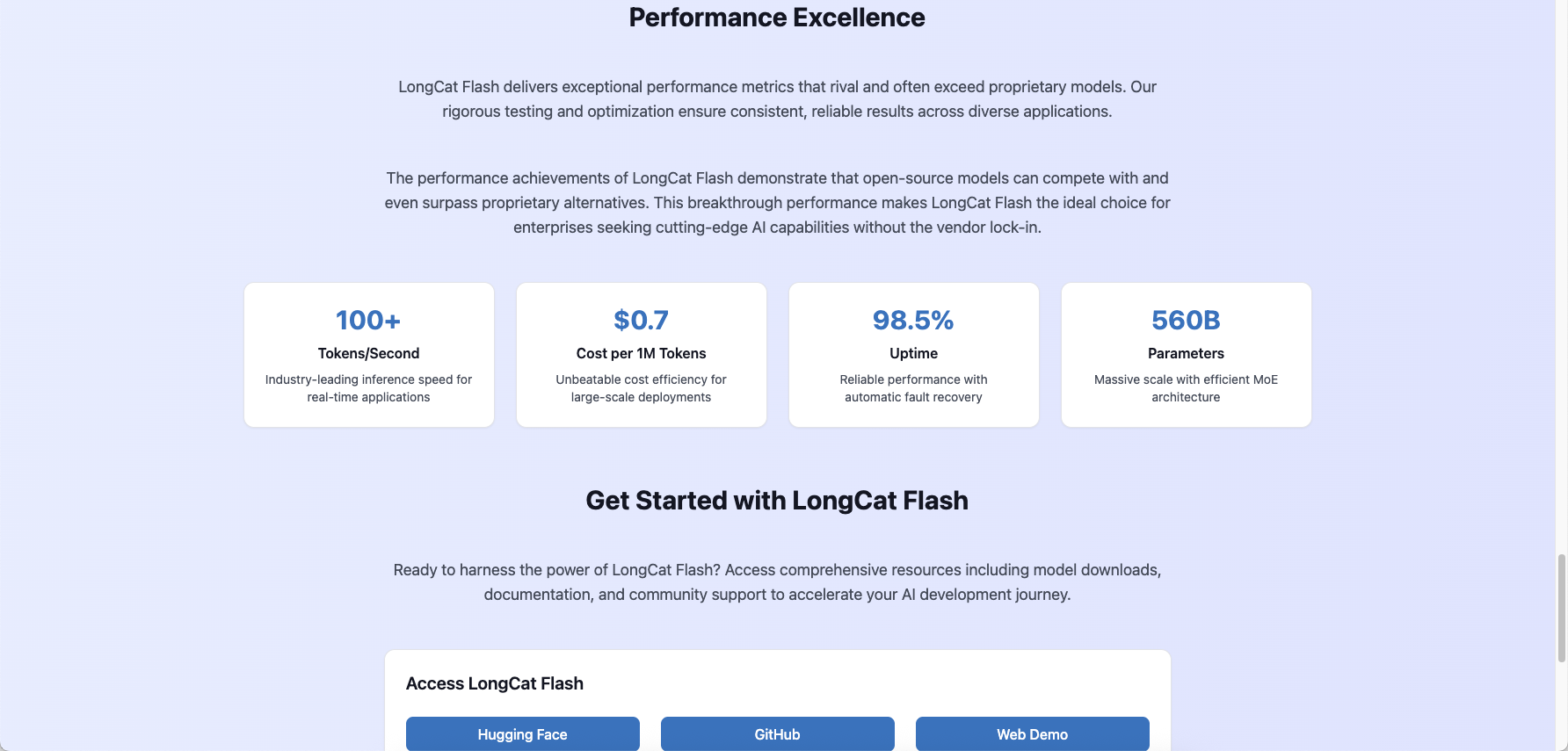
performance with over 100 tokens/second inference speed and costs as low
as $0.7 per million output tokens. The model excels in agentic
capabilities, complex reasoning, and real-world applications while
maintaining enterprise-grade reliability and scalability.


Features
- 560B Parameter MoE Architecture - Dynamically activates 18.6B-31.3B
parameters per token for optimal efficiency
- Blazing Fast Inference - Over 100 tokens/second on H800 GPUs with
minimal latency
- Cost-Effective Performance - Just $0.7 per million output tokens,
making it highly competitive
- Advanced Agentic Capabilities - Excels in tool use, multi-step
reasoning, and complex environment interaction
- Zero-Computation Experts - Smart resource allocation that saves
computation for simple tokens
- Shortcut-Connected MoE - Innovative architecture that reduces
communication bottlenecks
- Enterprise-Grade Reliability - 98.48% uptime with automatic fault
detection and recovery
- Open-Source Accessibility - Available on Hugging Face, GitHub, and web
demo for community use

Comments




At Imperial Security, https://imperialsecurity.agency we’re always looking for innovative technologies that can help us operate more efficiently — from managing client communications to enhancing our internal systems. LongCat Flash AI by Meituan has truly impressed us with its speed, intelligence, and scalability. With a massive 560B-parameter architecture and Mixture-of-Experts (MoE) design, this open-source AI model delivers exceptional performance and advanced reasoning capabilities. What stands out most is its blazing-fast inference speed — over 100 tokens per second — and cost efficiency, making it ideal for real-world business applications. We’ve found LongCat Flash AI particularly useful in automating reports, analyzing data, and assisting with AI-driven insights for operational planning. For a security company like ours, precision, reliability, and adaptability are essential — and LongCat AI delivers all three. It’s a powerful, enterprise-ready solution that proves open-source AI can compete with — and even outperform — many commercial models. Highly recommended for any business seeking to integrate advanced, cost-effective AI tools.
Premium Products





































Sponsors
BuyAwards
View all
Awards
View allMakers
Makers
Comments
At Imperial Security, https://imperialsecurity.agency we’re always looking for innovative technologies that can help us operate more efficiently — from managing client communications to enhancing our internal systems. LongCat Flash AI by Meituan has truly impressed us with its speed, intelligence, and scalability. With a massive 560B-parameter architecture and Mixture-of-Experts (MoE) design, this open-source AI model delivers exceptional performance and advanced reasoning capabilities. What stands out most is its blazing-fast inference speed — over 100 tokens per second — and cost efficiency, making it ideal for real-world business applications. We’ve found LongCat Flash AI particularly useful in automating reports, analyzing data, and assisting with AI-driven insights for operational planning. For a security company like ours, precision, reliability, and adaptability are essential — and LongCat AI delivers all three. It’s a powerful, enterprise-ready solution that proves open-source AI can compete with — and even outperform — many commercial models. Highly recommended for any business seeking to integrate advanced, cost-effective AI tools.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved