
We’re excited to launch Bifrost, the fastest and open-source LLM gateway.
At Maxim, our internal experiments with multiple gateways for our production use cases quickly exposed scale as a bottleneck. And we weren’t alone. Fast-moving AI teams echoed the same frustration -- LLM gateway speed and scalability were key pain points. They valued flexibility and speed, but not at the cost of efficiency at scale.
This motivated us to build Bifrost -- a high-performance LLM gateway that delivers on all fronts. Written in pure Go, Bifrost adds just 11μs latency at 5,000 RPS, and is 40x faster than LiteLLM. Key features:
🔐 Robust governance: Rotate and manage API keys efficiently with weighted distribution, ensuring responsible and efficient use of models across multiple teams
🧩 Plugin first architecture: No callback hell, simple addition/creation of custom plugins
🔌 MCP integration: Built-in Model Context Protocol (MCP) support for external tool integration and execution
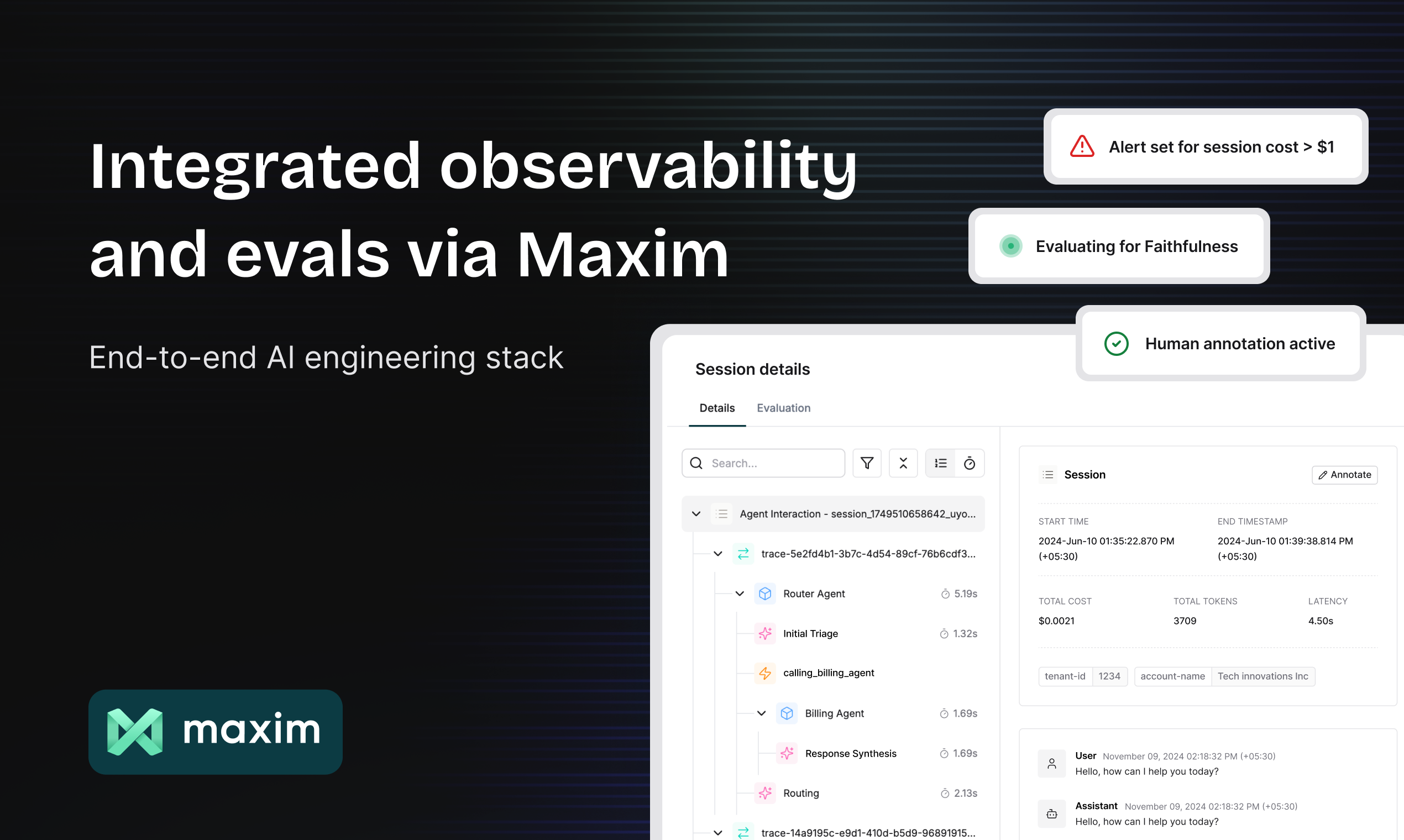
The best part? It plugs in seamlessly with Maxim, giving end-to-end observability, governance, and evals, empowering teams to ship AI products with the reliability and speed needed for real-world use.
We’re super excited to have you try it and share your feedback! You can get started today at getmaxim.ai/bifrost.



Features
- Built-in Web UI: Visual configuration, real-time monitoring, and analytics dashboard - no config files needed
- Zero-Config Startup & Easy Integration: Start immediately with dynamic provider configuration, or integrate existing SDKs by simply updating the base_url - one line of code to get running
- Multi-Provider Support: Integrate with OpenAI, Anthropic, Amazon Bedrock, Mistral, Ollama, and more through a single API
- Fallback Mechanisms: Automatically retry failed requests with alternative models or providers
- Dynamic Key Management: Rotate and manage API keys efficiently with weighted distribution
- Connection Pooling: Optimize network resources for better performance
- Concurrency Control: Manage rate limits and parallel requests effectively
- Flexible Transports: Multiple transports for easy integration into your infra
- Custom Configuration: Offers granular control over pool sizes, network retry settings, fallback providers, and network proxy configurations
- Built-in Observability: Native Prometheus metrics out of the box, no wrappers, no sidecars, just drop it in and scrape
- SDK Support: Bifrost is available as a Go package, so you can use it directly in your own applications

Comments


Hello PH community, I am Akshay from Maxim, and today we’re excited to officially announce the launch of Bifrost, a blazing-fast LLM gateway built for scale. What is it? Bifrost is the fastest, fully open-source LLM gateway that takes <30 seconds to set up. Written in pure Go (A+ code quality report), it is a product of deep engineering focus with performance optimized at every level of the architecture. It supports 1000+ models across providers via a single API. What are the key features? Robust governance: Rotate and manage API keys efficiently with weighted distribution, ensuring responsible and efficient use of models across multiple teams Plugin first architecture: No callback hell, simple addition/creation of custom plugins MCP integration: Built-in Model Context Protocol (MCP) support for external tool integration and execution The best part? It plugs in seamlessly with Maxim, giving end-to-end observability, governance, and evals empowering AI teams -- from start-ups to enterprises -- to ship AI products with the reliability and speed required for real-world use. Why now? At Maxim, our internal experiments with multiple gateways for our production use cases quickly exposed scale as a bottleneck. And we weren’t alone. Fast-moving AI teams echoed the same frustration – LLM gateway speed and scalability were key pain points. They valued flexibility and speed, but not at the cost of efficiency at scale. That’s why we built Bifrost—a high-performance, fully self-hosted LLM gateway that delivers on all fronts. With just 11μs overhead at 5,000 RPS, it's 40x faster than LiteLLM. We benchmarked it against leading LLM gateways - here’s the report. How to get started? You can get started today at getmaxim.ai/bifrost and join the discussion on Bifrost Discord. If you have any other questions, feel free to reach out to us at [email protected].
Premium Products





































Sponsors
BuyMakers
Makers
Comments
Hello PH community, I am Akshay from Maxim, and today we’re excited to officially announce the launch of Bifrost, a blazing-fast LLM gateway built for scale. What is it? Bifrost is the fastest, fully open-source LLM gateway that takes <30 seconds to set up. Written in pure Go (A+ code quality report), it is a product of deep engineering focus with performance optimized at every level of the architecture. It supports 1000+ models across providers via a single API. What are the key features? Robust governance: Rotate and manage API keys efficiently with weighted distribution, ensuring responsible and efficient use of models across multiple teams Plugin first architecture: No callback hell, simple addition/creation of custom plugins MCP integration: Built-in Model Context Protocol (MCP) support for external tool integration and execution The best part? It plugs in seamlessly with Maxim, giving end-to-end observability, governance, and evals empowering AI teams -- from start-ups to enterprises -- to ship AI products with the reliability and speed required for real-world use. Why now? At Maxim, our internal experiments with multiple gateways for our production use cases quickly exposed scale as a bottleneck. And we weren’t alone. Fast-moving AI teams echoed the same frustration – LLM gateway speed and scalability were key pain points. They valued flexibility and speed, but not at the cost of efficiency at scale. That’s why we built Bifrost—a high-performance, fully self-hosted LLM gateway that delivers on all fronts. With just 11μs overhead at 5,000 RPS, it's 40x faster than LiteLLM. We benchmarked it against leading LLM gateways - here’s the report. How to get started? You can get started today at getmaxim.ai/bifrost and join the discussion on Bifrost Discord. If you have any other questions, feel free to reach out to us at [email protected].
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved