
AI-Radar
Real-time AI news and analysis on LLMs and hardware
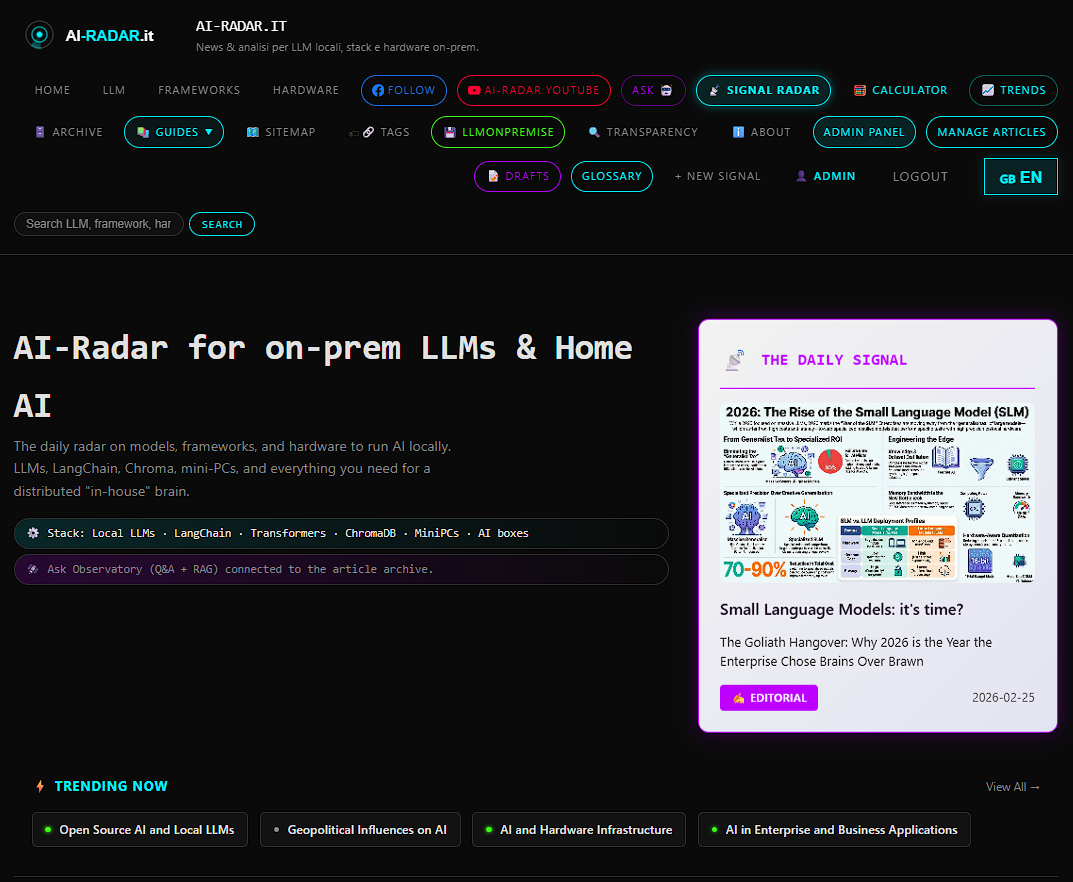
The daily radar on models, frameworks, and hardware to run AI locally. LLMs, LangChain, Chroma, mini-PCs, and everything you need for a distributed "in-house" brain.
Features
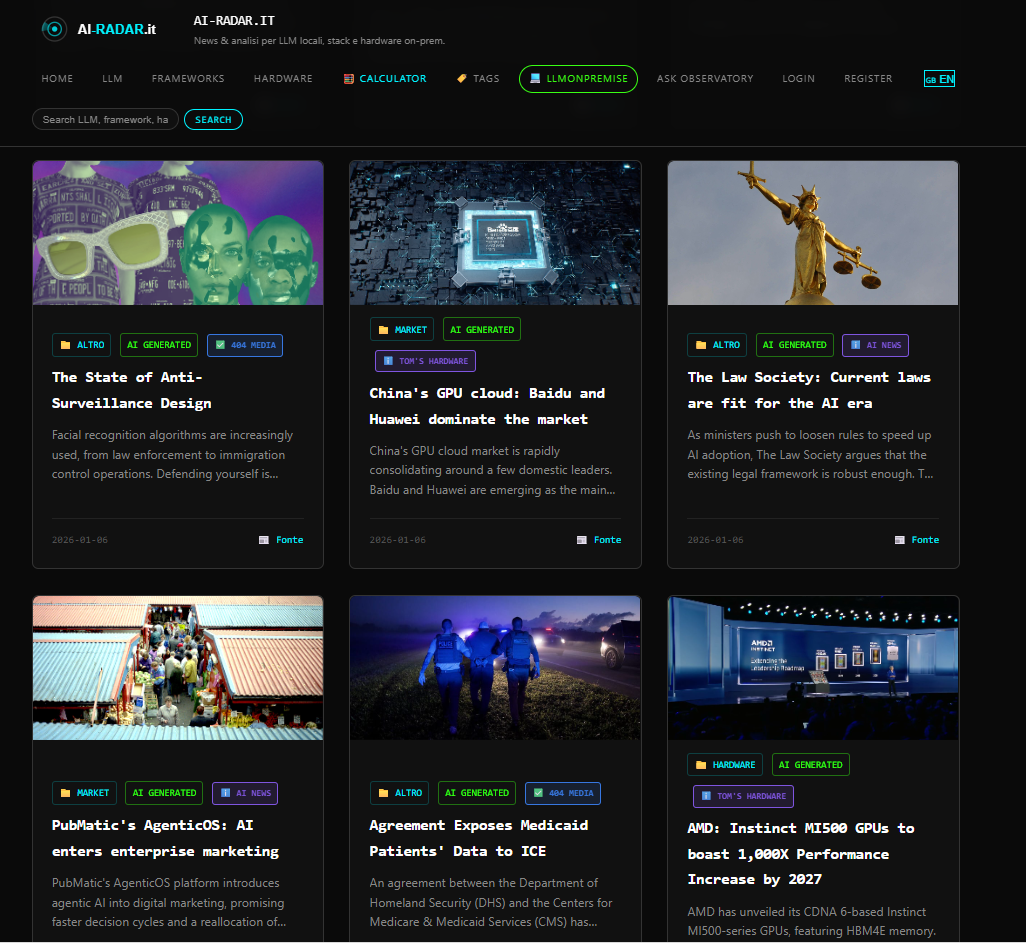
- AI-Radar is not the usual AI news aggregator. Technically speaking the App/site is totally handled via AI with a codebase based on Python, Postgre, Chroma DB and an Ollama LLM serving as article coordinator,helped by chatgpt handling other logics.
- It has a "Subsite" called LLMonPremise with a lot of technical infos on how to host locally LLMS and an internal grounded chatbot
Use Cases
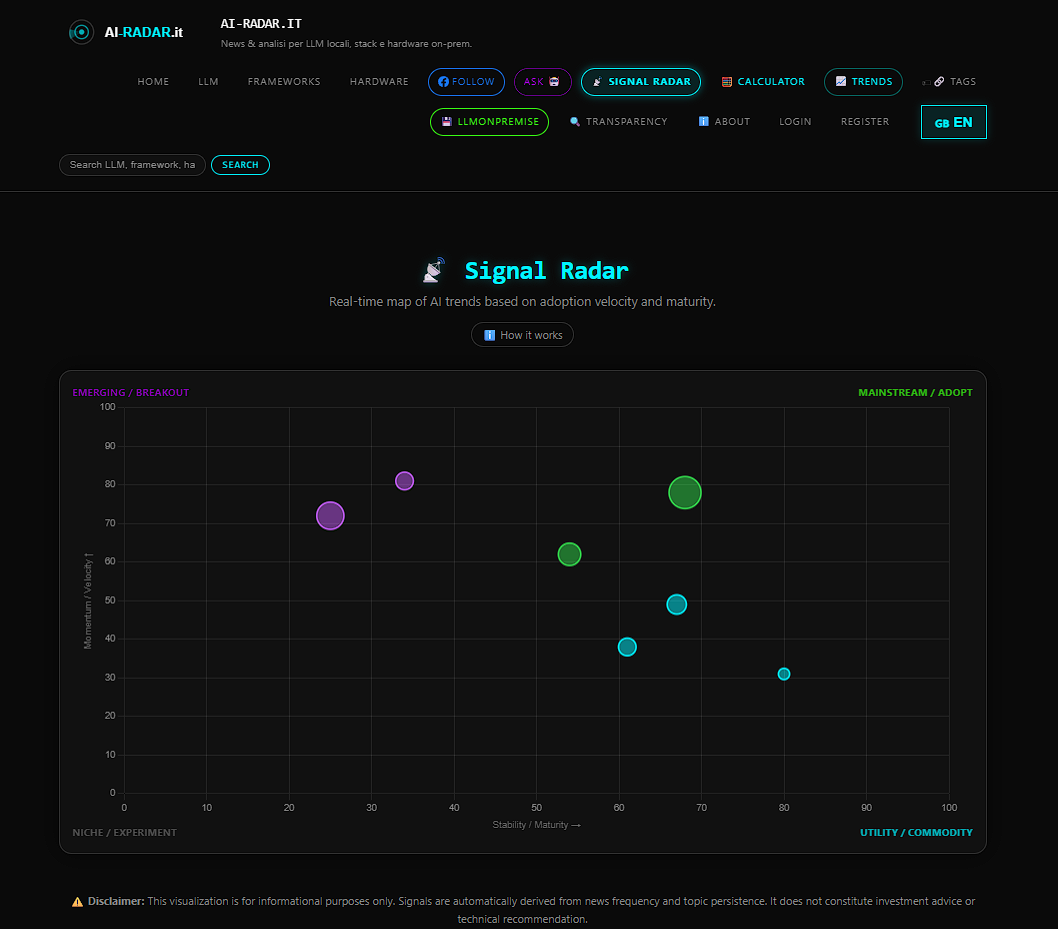
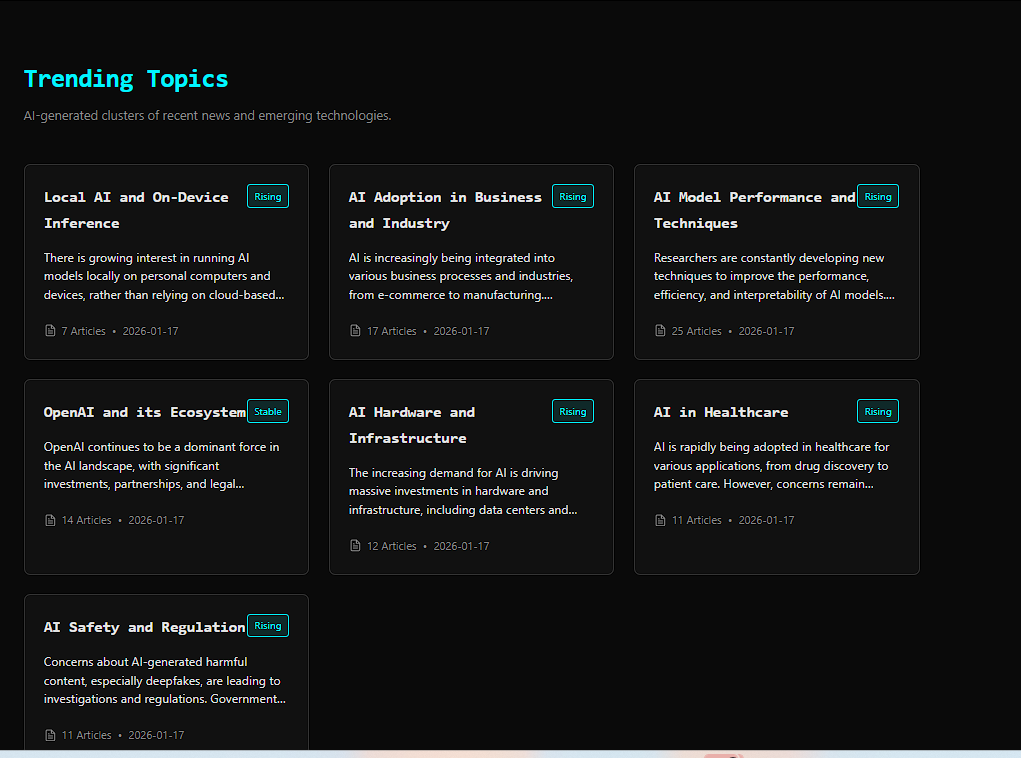
- AI Driven aggregator with dynamic contexts and a big news Archive.
- LlmOnPremise subsite with analsys,charts on local running AI models and relative hardware choices.
- Internal Grounded chatbot.

Comments












The fully AI-managed pipeline is a compelling architecture choice — using Ollama locally for article coordination while offloading other logic to a cloud LLM is a pragmatic way to balance cost and capability. The hardware filter idea from comments above is spot on: a section grouping news by deployment context (edge, M-series, consumer GPU) would make this much more actionable for builders. The Chroma DB integration for semantic search over the archive is the killer feature here — would love to see a public API endpoint for querying the news archive.
Premium Products































Sponsors
BuyAwards
View all
Awards
View allMakers
Makers
Comments
The fully AI-managed pipeline is a compelling architecture choice — using Ollama locally for article coordination while offloading other logic to a cloud LLM is a pragmatic way to balance cost and capability. The hardware filter idea from comments above is spot on: a section grouping news by deployment context (edge, M-series, consumer GPU) would make this much more actionable for builders. The Chroma DB integration for semantic search over the archive is the killer feature here — would love to see a public API endpoint for querying the news archive.
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved