
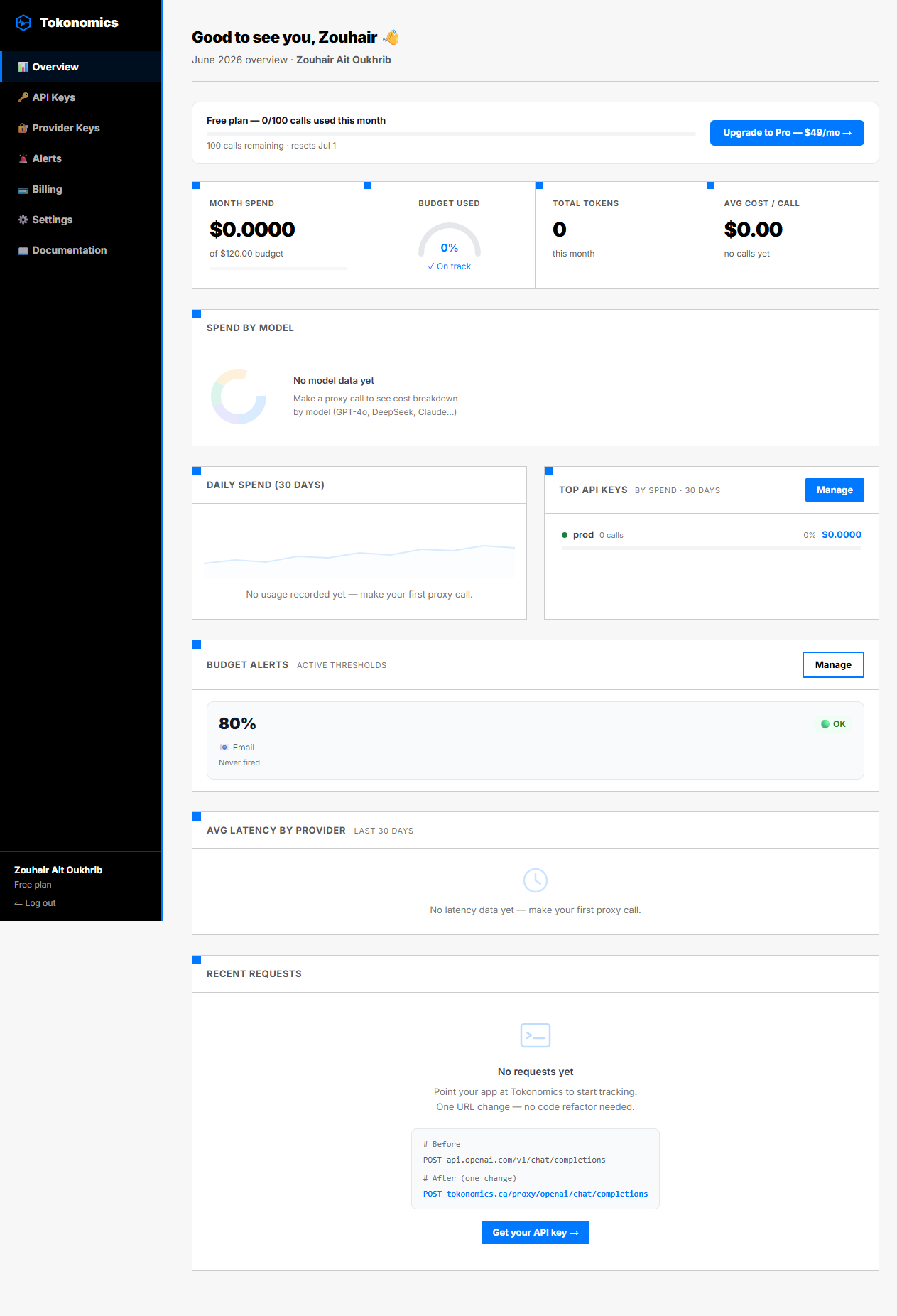
Tokonomics
Budget-first AI cost metering proxy for any stack
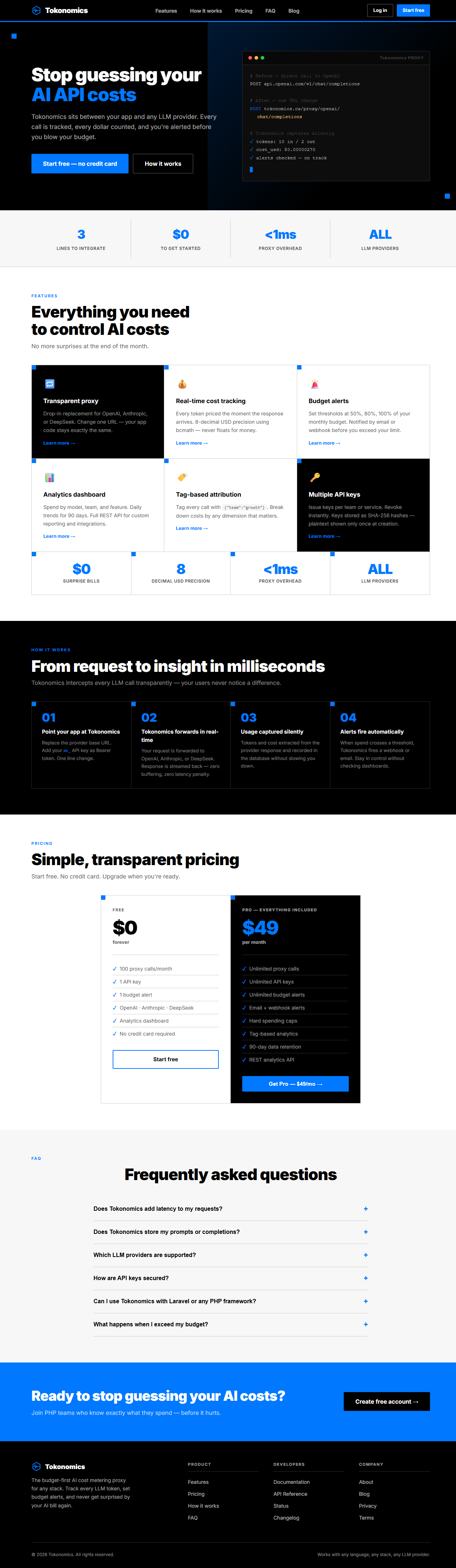
Tokonomics is an API proxy that sits between your app and any LLM provider (OpenAI, Anthropic, DeepSeek, Google Gemini, xAI, Mistral). It tracks every token, calculates cost per call, and enforces budget limits in real time. One line change in your code — works with any language and any HTTP client. Free tier available, Pro at $49/mo.
Features
• Real-time token tracking across all LLM providers
• Hard spending caps via Redis (sub-1ms budget checks)
• Budget alerts via email, Slack, and Microsoft Teams
• Per-feature and per-team cost breakdowns with custom tags
• AI cost optimization reports with model downgrade suggestions
• Rate limiting per API key (sliding window)
• Prompt cache savings tracking (OpenAI, Anthropic, DeepSeek, Gemini)
• 6 free developer tools (token counter, cost calculator, prompt optimizer, API builder, model matrix, ROI calculator)
Use Cases
• SaaS founders tracking AI costs per feature before they spiral
• Agencies isolating LLM spend per client with hard budget caps
• Startup CTOs generating monthly cost reports for board meetings
• ML engineers preventing runaway batch jobs with real-time alerts
• No-code builders (n8n, Make, Zapier) monitoring per-workflow AI costs
• Finance teams auditing AI spend across departments and teams

Comments


I built Tokonomics after receiving a $47,000 LLM invoice that nobody on my team saw coming. We had no visibility into which features were burning tokens, which models were overkill, or when spending crossed our budget. Existing tools were either observability-first (great for debugging, not for budgeting) or required you to rewrite your code with a specific SDK. Tokonomics is a proxy — one line change, any language, any provider. It tracks every token, enforces hard spending caps in real time, and sends alerts before you blow your budget. Free tier available, happy to hear your feedback!
Premium Products






















Sponsors
BuyMakers
Makers
Comments
I built Tokonomics after receiving a $47,000 LLM invoice that nobody on my team saw coming. We had no visibility into which features were burning tokens, which models were overkill, or when spending crossed our budget. Existing tools were either observability-first (great for debugging, not for budgeting) or required you to rewrite your code with a specific SDK. Tokonomics is a proxy — one line change, any language, any provider. It tracks every token, enforces hard spending caps in real time, and sends alerts before you blow your budget. Free tier available, happy to hear your feedback!
Premium Products
New to Fazier?

Find your next favorite product or submit your own. Made by @FalakDigital.
Copyright ©2025. All Rights Reserved